|
Dr. Paul Albert I am a Machine Learning scientist at Amazon's Melbourne Office. I graduated from my PhD at the Insight Centre for Data Analytics at the Dublin City University in Ireland in collaboration with the VistaMilk SFI research centre where I was mentored by the late Dr. Kevin McGuiness and Prof. Noel E. O'Connor. Prior working at Amazon I worked as a postdoctoral researcher at the Centre for Augmented Reasoning hosted at the Australian Institute for Machine Learning where I worked under the supervision of Dr. Jack Valmadre , Dr. Ehsan Abbasnejad and Prof. Anton Van Den Hengel.
Email / Google Scholar / Twitter(X) / Github |

|
ResearchI am interested in parameter efficient finetuning (PEFT), task vectors and low/no supervision machine learning and label noise. |
|
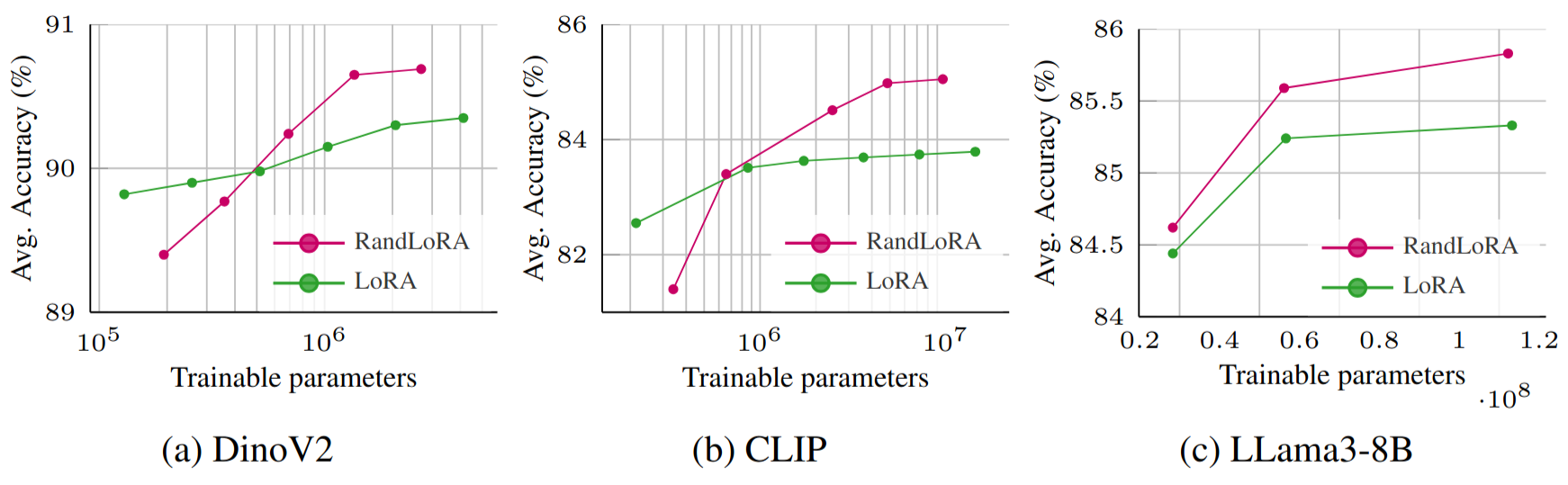
RandLoRA: Full rank parameter-efficient fine-tuning of large models
Paul Albert, Frederic Z. Zhang, Hemanth Saratchandran, Cristian Rodriguez-Opazo, Anton van den Hengel, Ehsan Abbasnejad In International Conference on Learning Representations (ICLR), 2025. project page / arXiv / code We present RandLoRA, a full rank parameter efficient algorithm that combines fixed random matrices. We show the rank-bound limitations of LoRA and show that for an equal number of trainable parameters, RandLoRA outperforms LoRA accross vision-language (CLIP) and language (commonsense reasoning) tasks. RandLoRA additionally uses less VRAM than LoRA when training, making it particualrily suitable for large model tuning. |
|
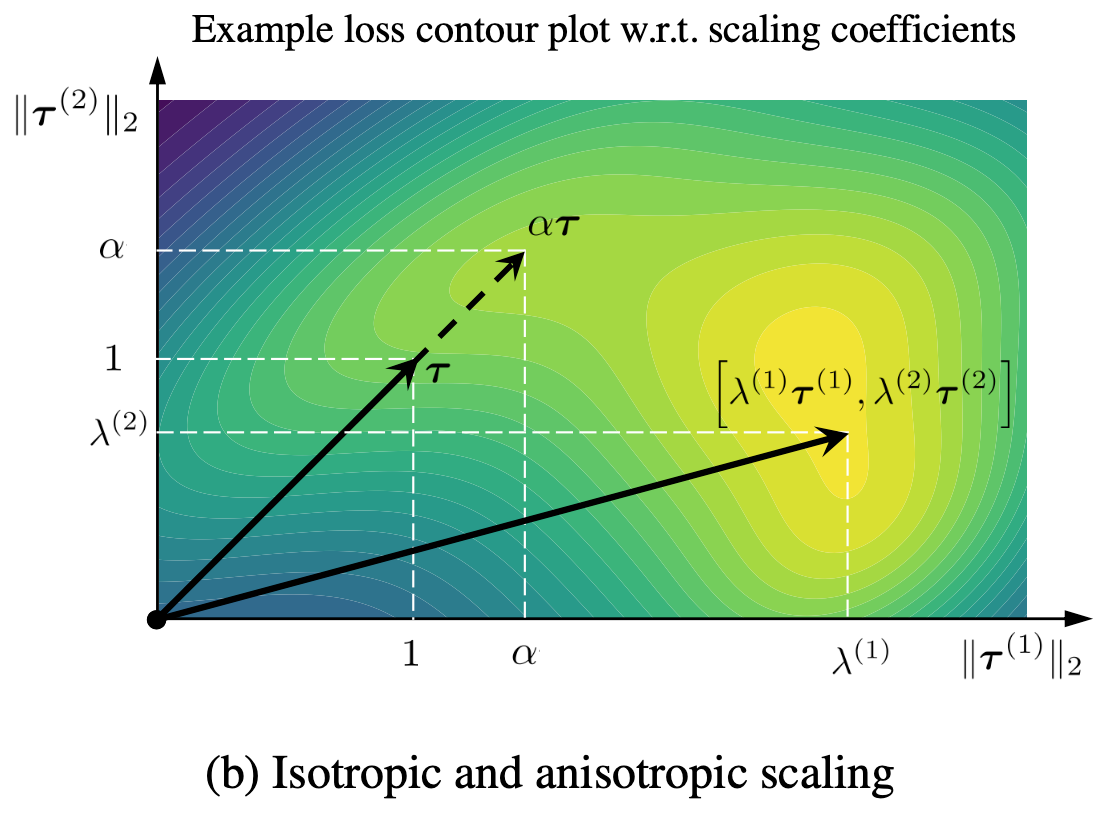
Knowledge Composition using Task Vectors with Learned Anisotropic Scaling.
Frederic Z. Zhang*, Paul Albert*, Cristian Rodriguez-Opazo, Anton van den Hengel, Ehsan Abbasnejad. In Advances in Neural Information Processing Systems (NeurIPS), 2024. arXiv / code We present aTLAS, a parameter efficient algorithm that learns to combine task vectors in an anisotropic manner. We additionally apply task vectors to solve new tasks, including generalization and test-time adaptation. * equal contribution |
|
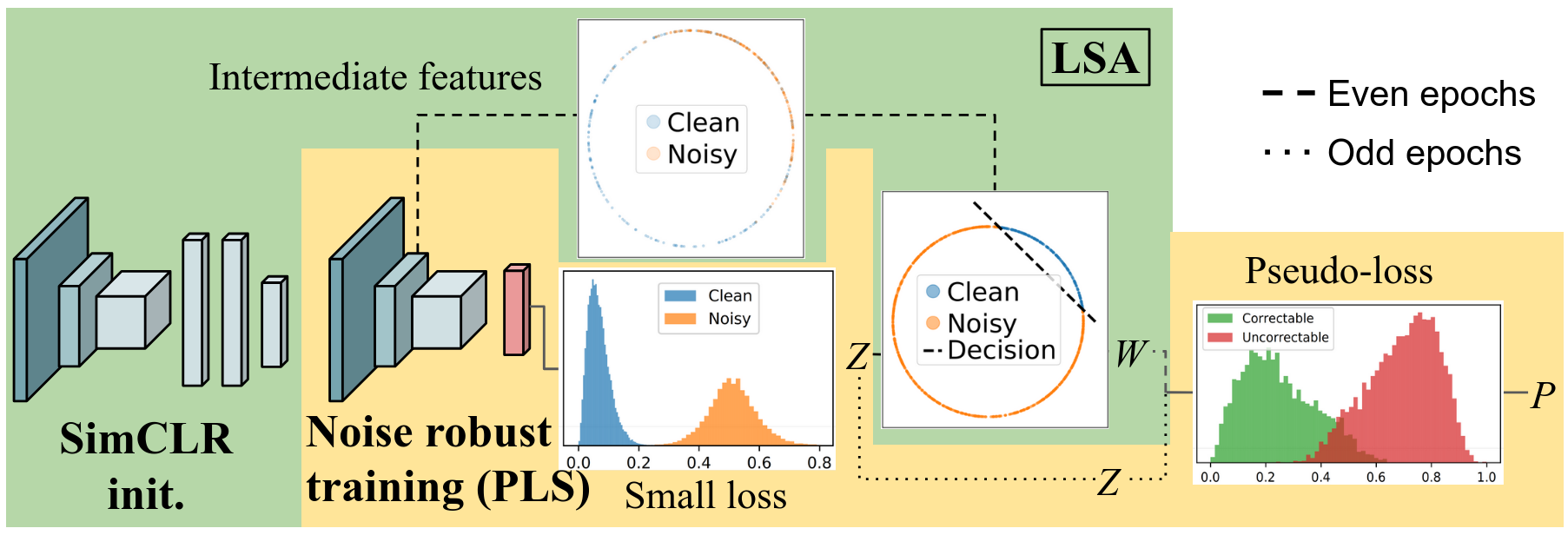
An accurate detection is not all you need to combat label noise in web-noisy datasets.
Paul Albert, Jack Valmadre, Eric Arazo, Tarun Krishna, Noel E. O'Connor, Kevin McGuinness In Proceedings of the European Conference on Computer Vision (ECCV), 2024. arXiv / code We observe that contrastive learning linearly separates web noisy samples in early layers of neural networks. Some of the miss-detected samples from the linear separation samples are however highly important and should be trained on. We then use an alternating detection strategy between linear separation and small loss to perform an accurate detection. |
|
Thanks to Barron's website template. |